




LMAX Exchange
Introducing ConcurrentHashTrie
While spending some time looking at Clojure’s concurrency model, I did a little bit of research into their persistent collection implementation that uses Bagwell’s Hash Array Mapped Tries.
After a little bit of thought it occurred to me that you could
apply the persistent collection model to an implementation of ConcurrentMap. The simple solution would be to maintain a reference to a persistent map within a single AtomicReference and apply a compareAndSet (CAS) operation each time an update to the map was performed. In Clojure terms, a ref and swap! operation. However a typical use of ConcurrentMap
is for a simple cache in a web application scenario. With most
web applications running with fairly significant numbers of threads
(e.g. 100’s) it’s conceivable that the level of contention on a single
compare and set operation would cause issues. Non-blocking
concurrent operations like compare and set work really well at avoiding
expensive user/kernel space transitions, but tend to break down
when the number of mutator threads exceeds the number of available
cores*. In fact thread contention on any concurrent access control
structure is a killer for performance. The java.util.ConcurrentHashMap uses lock-striping as a mechanism to reduce contention on writes. If absolutely consistency across the ConcurrentMap was sacrificed (more information below), then a form of “CAS striping” could be applied to the ConcurrentHashTrie to reduce contention. This is implemented by replacing the AtomicReference with an AtomicReferenceArray and using a hash function to index into the array.
The Implementation
There
are a number of implementations of the Bagwell Trie in JVM languages,
however I couldn’t find an implementation in plain old Java, so I wrote one myself. For the persistent collection it follows a fairly standard polymorphic tree design.
The
core type of Node has 3 implementations. The key one is the
BitMappedNode, which handles the vast majority of branch nodes and
implements the funky hash code partition and population count operations
that make up the Bagwell Trie structure. LeafNode holds the
actual key/value pairs and ListNode is there to handle full collisions.
The key mutator methods of ConcurrentMap: put, putIfAbsent, remove and replace are implemented using CAS operations on the rootTable, which is an AtomicReferenceArray.
As mentioned earlier, the ConcurrentHashTrie
is not consistent for operations that occur across the entire
structure. While at first look this seems terrible, in practical
terms it is not really an issue. The 2 main operations this
impacts are size and iteration. The size operation in the
ConcurrentHashTrie is not O(1), but is O(n) where n is the size of the rootTable (or the number of stripes). Because it has to iterate across all of the nodes in the rootTable
(it doesn’t need to traverse down the trees) and add all of their sizes
it possible for the size of a Node to change after it has been read but
before the result has been calculated. Anyone that has worked a
concurrent structure before has probably found that the size
value is basically useless. It is only ever indicative, as the
size could change right after the method call returns, so locking the
entire structure while calculating the size doesn’t bring any benefit.
Iteration follows the same pattern. It is possible that a
node could have changed after being iterated over or just before being
reached. However, it doesn’t really matter as it is not really any
different to the map changing just before iteration started or just
after it completes (as long as iteration doesn’t break part way
through). Note that Cliff Click’s NonBlockingHashMap exhibits similar behaviour during iteration and size operations.
Performance, The Good, The Bad and the… well mostly Bad
Cliff Click kindly included a performance testing tool with his high scale library which I’ve shamelessly ripped off
and used to benchmark my implementation. Apparently he borrowed
some code from Doug Lea to implement it. I changed a sum total of 1
line. Writing benchmarks, especially for concurrent code, is very
tough (probably harder than writing the collection itself), so
borrowing from the experts gives me some confidence that the numbers I
produce will be useful.
So onto the results:
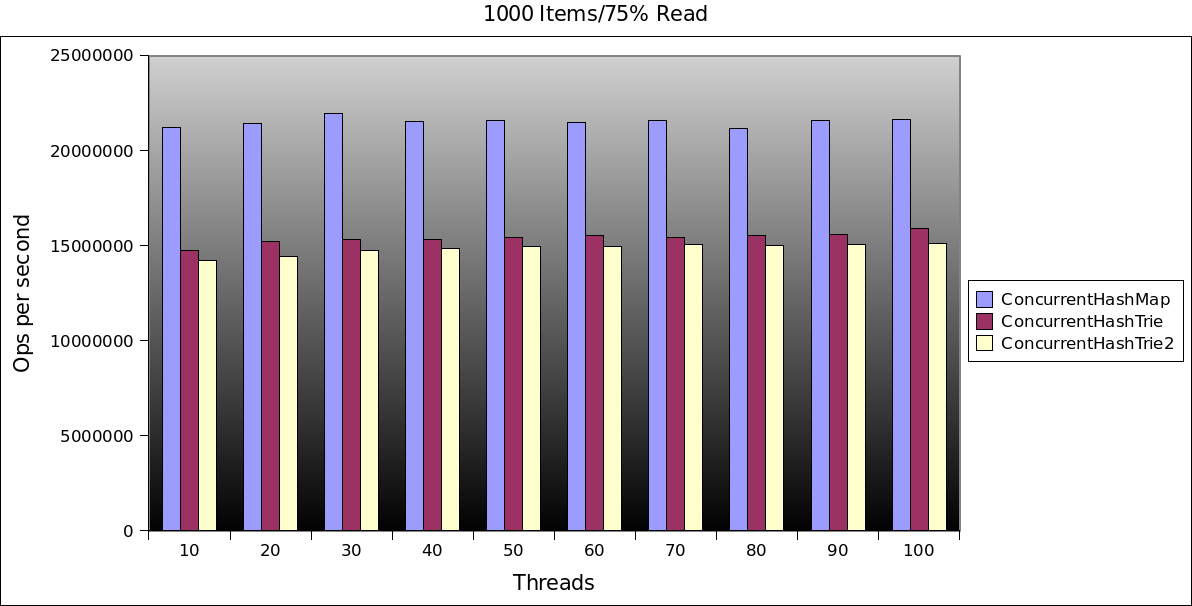
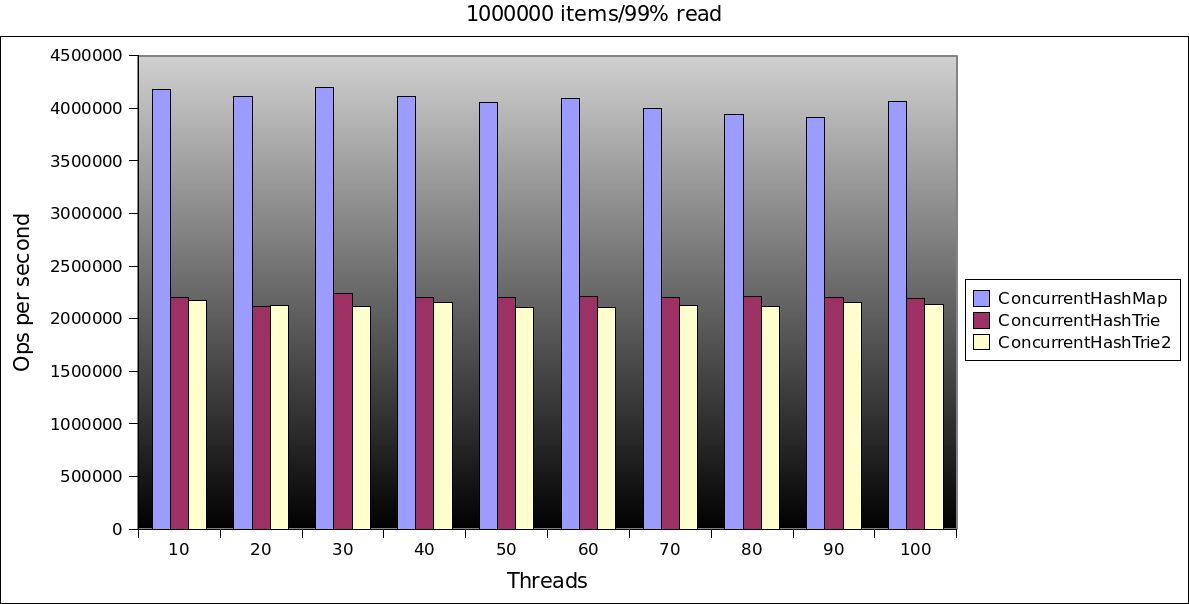
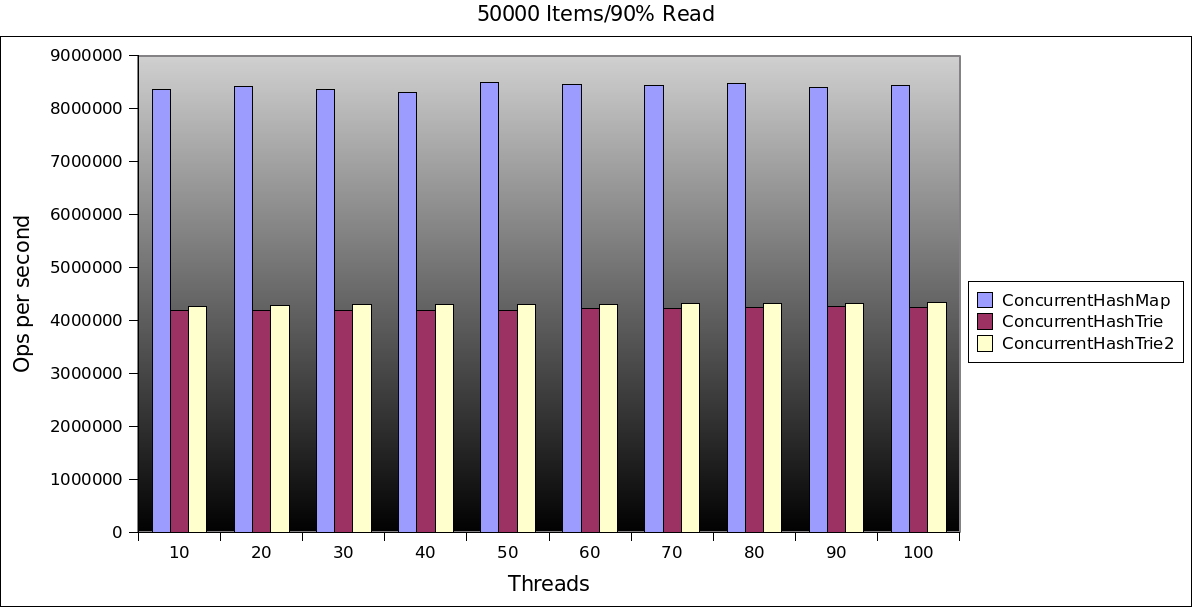
Do’h!!
Quite a bit slower than the java.util.ConcurrentHashMap. I didn’t even bother comparing to the NonBlockingHashMap from the high scale library, the numbers would be too embarrassing.
The ConcurrentHashTrie2
is an alternative implementation that I experimented with. I
suspected the polymorphic behaviour of the tree nodes was causing a
significant performance hit due to a high number of v-table calls.
The alternate implementation avoids the v-table overhead by
packing all three behaviours into a single class (in a slight dirty
fashion). I stole a couple of bits from the level variable to
store a discriminator value. The Node class switches on the
discriminator to determine the appropriate behaviour. As the
results show, it didn’t help much. I ran a number of other
permutations and the results were largely the same.
Conclusion
So
a question remains, is the approach fundamentally flawed or is my code
just crap? I suspect the major cost is caused by heavy amount of
memory allocation, copying and churn through the CPU cache caused by the
path-copy nature of mutation operations. Also the read path isn’t
particularly quick. With a reasonably full map, reads will likely
need to travels a couple of levels down the tree. With the
traditional map, its a single hash and index operation.
* I
really need a proper citation for this. However imagine 16 cores
and a 100 threads trying to apply a compare and set operation to the
same reference. Unlike a lock which will park the threads that
fail to acquire the lock, non-blocking algorithms require the thread
that fails to apply its change to discard its result and recompute its
result, effectively spinning until is succeeds. With more CPU
bound threads than cores, its possible that the system will end up
thrashing.