




LMAX Exchange
…indeed, your life might get simpler if you don’t.
This post will talk through two examples where clever serialization would have been an option, but stupid alternatives actually turned out to be preferable.
Example 1: An LMAX deployment tool
We tried to make a piece of one of our deployment tools a little better, and in doing so we broke it in a very interesting way.
Breaking it
Please be aware, the following code snippet is in groovy, not java.
@Override
void accept(String serviceName, List<TopicEndPoint> topics)
{
// FIXME: this is highly suspicious. Why are we collecting as TEP when it is TEP already?
List<TopicEndPoint> topicDetailsList = topics.collect { it as TopicEndPoint }
This code is in the part of this tool that checks that all of our reliable messaging components agree on sequence numbers. We couldn’t find any reason for that particular use of groovy‘s as operator, so we replaced it the following:
List<TopicEndPoint> topicDetailsList = topics == null ? Collections.emptyList() : topics;
That made all of our tests pass, so we felt safe to ship. One groovy idiom fewer (we’re trying to migrate all our groovy back to java; we’re not good groovy programmers, and we like our type safety enforced rather than optional).
Some time later
An email arrives from a colleague.
Hey folks, I reverted your change to TopicSequenceMismatchFinder.groovy. It bails out with an exception when we try to check the system is in sync in staging. It's quite an odd exception: "Cannot cast groovy.json.internal.LazyMap to TopicEndPoint" Better luck next time!
Back to the drawing board
Oh well, we thought, at least the as is explicable now – it probably has the smarts to turn LazyMap into TopicEndPoint, assuming the structure of the decoded json looks right. We were somewhat peeved that List had been allowed to masquerade as List all the way down to here, though, so we set off in search of precisely whereabouts this had been allowed to happen.
Those of you with a keen sense of inference will have guessed where we ended up – in a serialization layer.
How this deployment tool talks
We have a set of servers on which we run the various applications that make up an exchange instance. Each of those servers has a deployment agent process running on it to allow coordination of actions across that environment. Those agents all talk to the same deployment server which provides a single point to perform maintenance on that environment.
At the point where we check the system is in sync, the server sends each connected agent a command: reportTopicDetails. The agents respond asynchronously. When the server has received a response from every agent, it collects the results together and calls into our TopicSequenceMismatchFinder class to see if everything is OK.
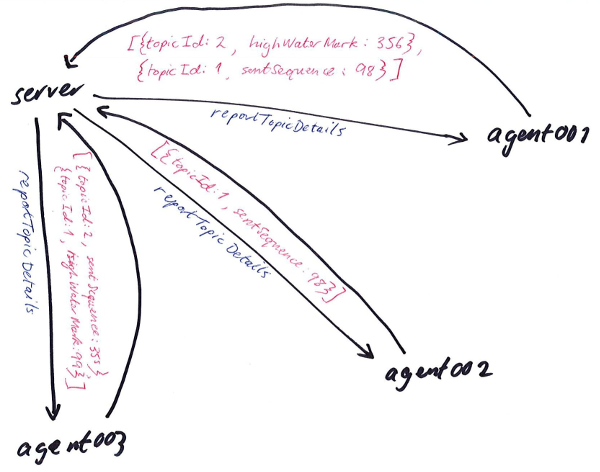
Server -> Agent -> Server communication in a bit more detail
So, the server sends commands to the agent, and the agent (eventually) responds with the results. We wrap up the asynchronicity in a class named RemoteAgent which allows a part of the server to pretend that these RPCs are synchronous.
The trouble starts when we deserialize that response from the agent. A part of its response is generic; the full format roughly looks like this class.
public class LocalCommandResult<T>
{
private static final Gson GSON = new Gson();
private long correlationId;
private boolean success;
private Map<String, T> returnValue;
private String details = "";
private String hostName;
}
At the point where a response arrives from an agent, we look up the command that is in flight and ‘complete’ it with the deserialized response.
@Override
public void reportCommandResult(final long correlationId, LocalCommandResult result)
{
this.lastUpdated = System.currentTimeMillis();
final RemoteCommandResult status = inFlightCommandResultByCorrelationId.remove(correlationId);
if (status != null)
{
status.complete(result);
}
}
The keener eyed reader will already have noticed the lack of generics on that LocalCommandResult. Indeed this is the problem – the T varies depending on the command being handled by the agent.
The deserialization layer is highly clever in some ways; it’s been built to manage arbitrary RPCs from agent to server, not just command responses. This makes it quite difficult to instruct it what type to use to deserialize any given LocalCommandResult‘s inner details into; so it cheats, and leaves it as LazyMap, forcing that as cast later on. It’s also written in groovy, which we want to migrate away from.
We took a look at the different RPCs we sent from agent to server and discovered there were precisely four of them. Not nearly enough to require something as clever as the existing groovy! We quickly knocked together a pure java implementation. We also made reportCommandResult subtly different:
void reportCommandResult(long correlationId, LocalCommandResult<JsonElement> result)
^^^^^^^^^^^^^
If it feels odd that our serialization layer calls us with an only partially deserialized result, this post is for you. Yes, we’re now done with the motivation part of this example, and we’re heading into the actual content.
Why partial deserialization?
Well, in this case, it’s a question of who knows what. We could, just before we fire off the command to the agent, inform the serialization layer what type to deserialize that command’s eventual result as.
This would mean storing two things by the correlation id in different layers. The serialization layer would hold a map of correlation id to expected return type, and RemoteAgent a map of correlation id to something that looks a bit like CompletableFuture<LocalCommandResult>.
It feels uncontroversial to prefer the system that has to maintain less state. If we inform RemoteCommandResult what type it will be completed with (via TypeToken or similar), it can complete the parsing of the response when it is completed. It even has the option to transform the parse error into a failing result and propagate it upstream.
private final java.lang.reflect.Type type;
void complete(LocalCommandResult<JsonElement> result) {
futureResult.set(parseTypedResult(result))
}
private LocalCommandResult parseTypedResult(LocalCommandResult<JsonElement> result)
{
if (result.getReturnValue() == null)
{
return new LocalCommandResult<>(result.getCorrelationId(), result.getSuccess(), null, result.getDetails(), result.getHostName());
}
else
{
final Map<String, Object> actualResults =
result.getReturnValue().entrySet()
.stream()
.collect(
Collectors.toMap(
Map.Entry::getKey,
entry -> GSON.fromJson(entry.getValue(), type)));
return new LocalCommandResult<>(result.getCorrelationId(), result.getSuccess(), actualResults, result.getDetails(), result.getHostName());
}
}
What we’ve done here is choose a generic enough class for serialization that the java generic piece can be deferred to a different point in our program.
An option we ignored
At the time, we did not consider changing the sending side to make it include type information. That might have made this example moot, assuming that all of those types are addressable by the serialization layer.
Example 2: Reducto
Another example of generics-via-generic-object
In our first example, our universal type was JsonElement. We could have gone lower and used String. Or lower still and gone for ByteBuffer or byte[]. Fortunately, in the weeks before our problems with LazyMap I’d done just this in a side project, reducto.
Reducto is a very simple map reduce like project that focusses on data that is indexed by time (or, to be precise, indexed by a single, long, column). So every piece of data in reducto is (timestamp, something) where the type of something is user defined.
Items get grouped together in buckets that span a particular time period. Those buckets are then distributed across an arbitrary number of agent processes, and you can do the usual Amdahl sympathetic map reduce pattern across those agents in parallel.
For an end user, a reduction needs the following pieces:
public final class ReductionDefinition<T, U, F>
{
public final Supplier<U> initialSupplier;
public final BiConsumer<U, T> reduceOne;
public final BiConsumer<U, U> reduceMany;
public final Serializer<U> serializer;
public final FilterDefinition<F, T> filterDefinition;
public ReductionDefinition(
Supplier<U> initialSupplier,
BiConsumer<U, T> reduceOne,
BiConsumer<U, U> reduceMany,
Serializer<U> serializer,
FilterDefinition<F, T> filterDefinition)
{
this.initialSupplier = initialSupplier;
this.reduceOne = reduceOne;
this.reduceMany = reduceMany;
this.serializer = serializer;
this.filterDefinition = filterDefinition;
}
}
N.B I can hear the screaming already. Where are the functions? Why are those things all consumers? We’ll talk about this another time, I promise…
Now, this means that, at some point, reducto is going to have to send U values from agent to server, in order to assemble the completely reduced result.
Here’s the shape of the RPC between the agent and the server to do just that, with one type removed.
interface AgentToServer
{
void bucketComplete(
String agentId,
String cacheName,
long iterationKey,
long currentBucketKey,
??? result);
}
Now, what should the type of result be? Does it help to know that, at the network layer, the agent is talking to the server over a TCP socket, using a custom binary protocol?
The loveliest answer would probably be Object, with the actual object magically being the correct U for whatever reduction is (con?)currently in progress.
We could certainly make this the case, but what would that mean for the design of the server?
Perhaps a better question would be: who knows how to deserialize that type from a binary blob? The reduction definition. How do we know which reduction definition this particular ‘message’ applies to? Well, we need to look at the cacheName and the iteration key. The parameters are coming from inside the RPC we’re trying to deserialize. To make this work, serialization would have to look like this:
final String agentId = readString(stream);
final String cacheName = readString(stream);
final int iterationKey = readInt(stream);
final int bucketKey = readInt(stream);
final Deserializer deserializer = server.findDeserializer(cacheName, iterationKey);
final Object o = deserializer.readObject(stream);
server.bucketComplete(
agentId,
cacheName,
iterationKey,
bucketKey,
o);
That’s average for two reasons – we’ve broken the nice encapsulation the server previously exercised over serialization knowledge. Just as bad – what are we going to do first in the bucketComplete call? We’re going to look up this iteration using the same two keys again.
We could completely mix the deserialization and server layers to fix this, but that feels even worse.
We could, again, put some type information inside the stream, but that still would need some sort of lookup mechanism.
If you aren’t convinced these alternatives are worse, imagine writing tests for the serialization layer for each until you do. It shouldn’t take long.
What’s the answer? Surely you can guess!
void bucketComplete(
String agentId,
String cacheName,
long iterationKey,
long currentBucketKey,
ByteBuffer result);
Once again, we defer parsing that result until later; and again, at the point where we do that, the options for error handling are better. We keep reducto‘s own RPC layer blissfully unaware of whatever terrifying somethings end users might dream of. The TimeCacheServer interface remains a messaging contract. Tests are gloriously simple to write.
The only regrettable outcome is the lack of deployable generics voodoo; we’ll have to find somewhere else to score those points.
Conclusion
This envelope/layering trick turns up everywhere in the world of serialization. Most TCP or UDP packet handling code will throw up an immediate example – we don’t usually pass deserialization equipment to a socket – it passes us bytes now and again, assuming we will know what they are.
We shouldn’t be overly concerned if, at some point downstream, we pass some of those unparsed bytes (or even a parsed intermediate format) on to someone else, who might know better what to do with them.
Next time
Most of these decisions are driven from trying to write tests, and suddenly finding that it is hard to do so. Now we’ve got our encapsulation in the right place, what testing benefits will we receive?