




LMAX Exchange
The journey did not end at that point, and we carried on testing to see if we could improve things even further. Our initial upgrade work involved changing the file-system from ext3 to ext4 (reflecting the default choice of the kernel version that we upgraded to).
However, it turns out that there is quite a lot of choice available in the kernel in terms of file-systems. After doing a little reading, it seemed as though it would be worth trying out xfs for our journalling file-system.
The rest of this post looks at the suitability of the xfs file-system for a very specific workload.
At LMAX our low-latency core services journal every inbound message to disk before they are processed by business-logic, giving us recoverability in the event of a crash. This has the nice side-effect of allowing us to replay events at a later date, which has proven invaluable in tracking down the occasional logic error.
Due to the nature of our workload, we are interested in write-biased, append-only performance. This is in contrast to a database or desktop system, which will necessarily require a more random access strategy.
Test Setup
Over the years, our journalling code has acquired some performance-related features. While running on ext3, we found that the best performance was achieved by preallocating file blocks, and using a reader thread to ensure that the files were hot in the kernel’s page cache before attempting to write to them.
We could assume that this feature will still be beneficial when using ext4 and xfs, since it seems logical that keeping things cache-hot and reducing the work needed to write will make things quicker. When making such a fundamental change to a system though, it’s best to re-validate any previous findings.
In order to do this, I ran three different configurations on each file-system:
1) no pre-allocation of journal files – i.e. first write creates a sparse file and writes to it
2) pre-allocate sparse files – i.e. the inodes exist, but size-on-disk is zero
3) pre-allocate and fill files – i.e. write zeroes for the total file-length so that the page-cache can be populated
Initial Results
The test harness records a full histogram of write latencies over the course of several test runs, these data can be used to inspect the difference in maximum write latency for each configuration:
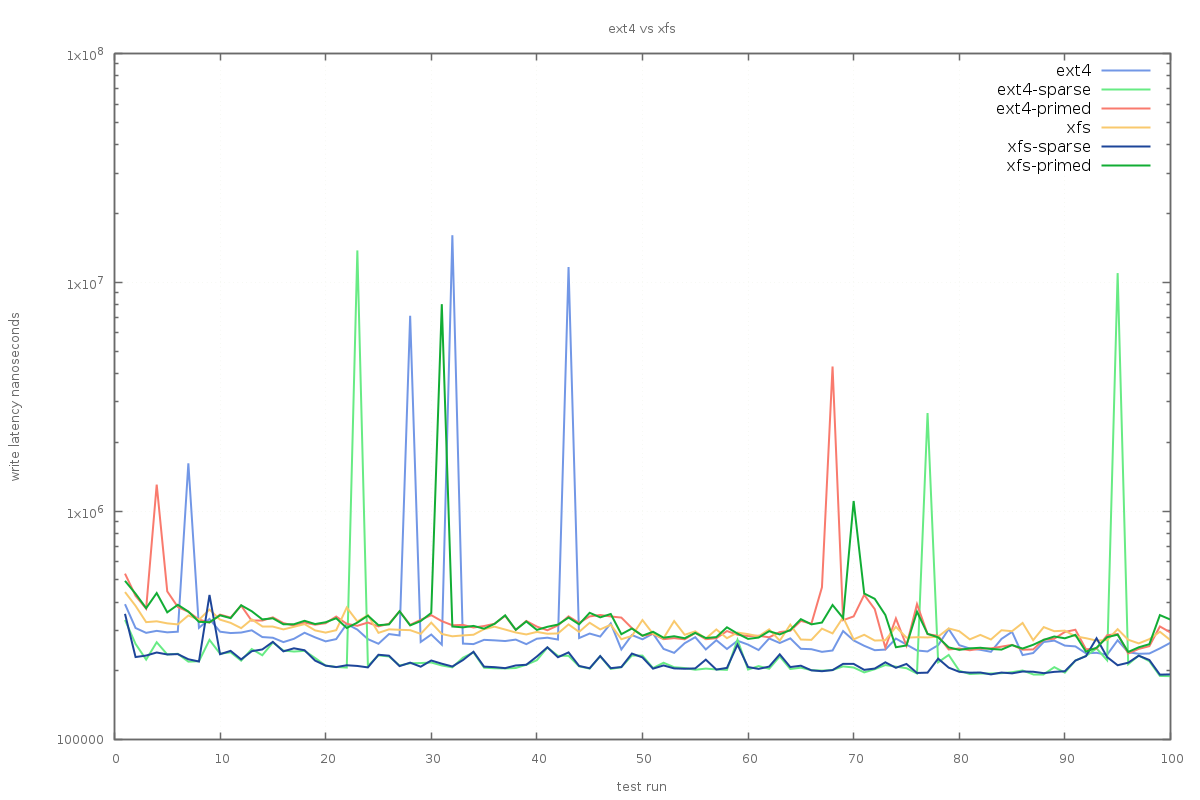
The best results are from xfs when there is sparse pre-allocation; actually priming the pages before writing does not seem to make things any better. This result isn’t particularly intuitive, but seems to hold true for ext4 also. For all configurations on ext4, multi-millisecond write latencies are apparent.
In order to get an idea of what sort of write performance we can expect most of the time, we can look at the mean write latency over the same set of experiment data:
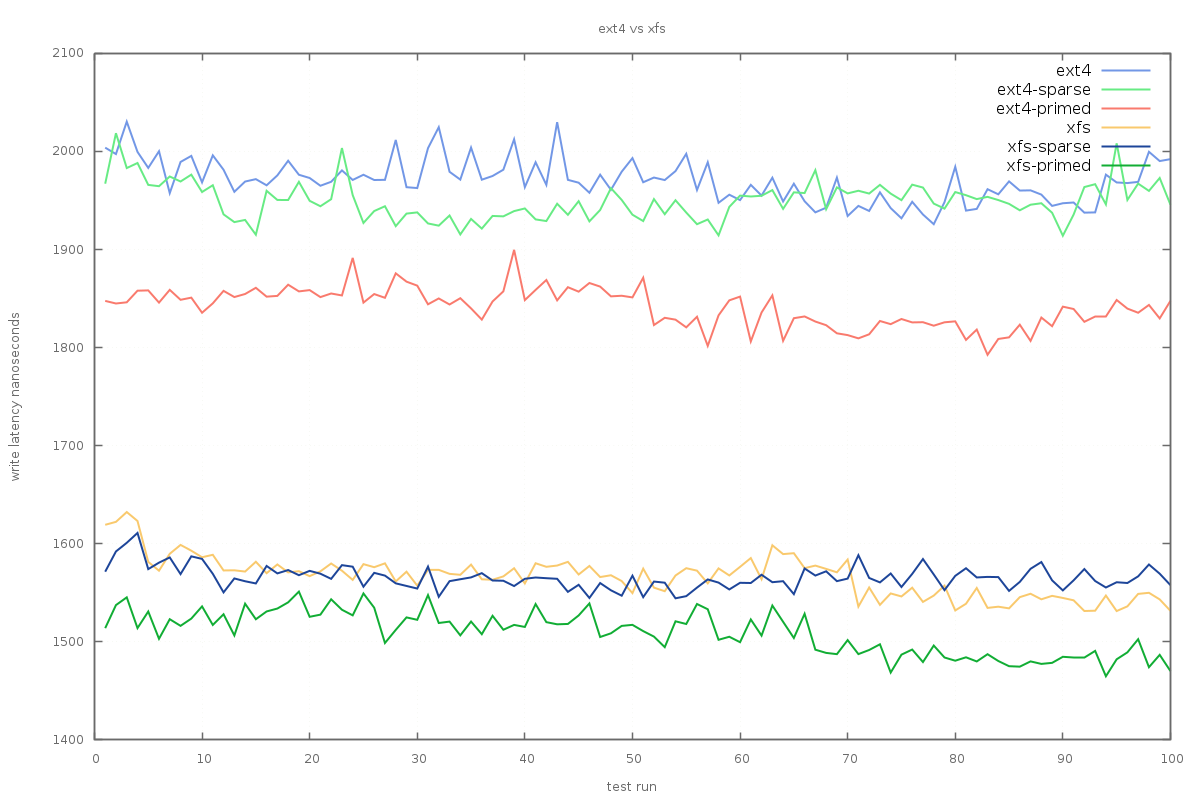
Here it’s clear that xfs gives better results, with the average write beating all ext4 modes by a few hundred microseconds. Interestingly, in the average case, pre-allocating and priming files seems to give the best results for both file-systems. This result fits better with intuition, since writes to existing cache-hot pages should be doing less work.
So far, the average and worst-case latencies seem to be best served by using xfs with sparsely allocated files. Looking more closely at the results however shows that ext4 has a better four-nines latency profile when writing to fully-primed journal files:
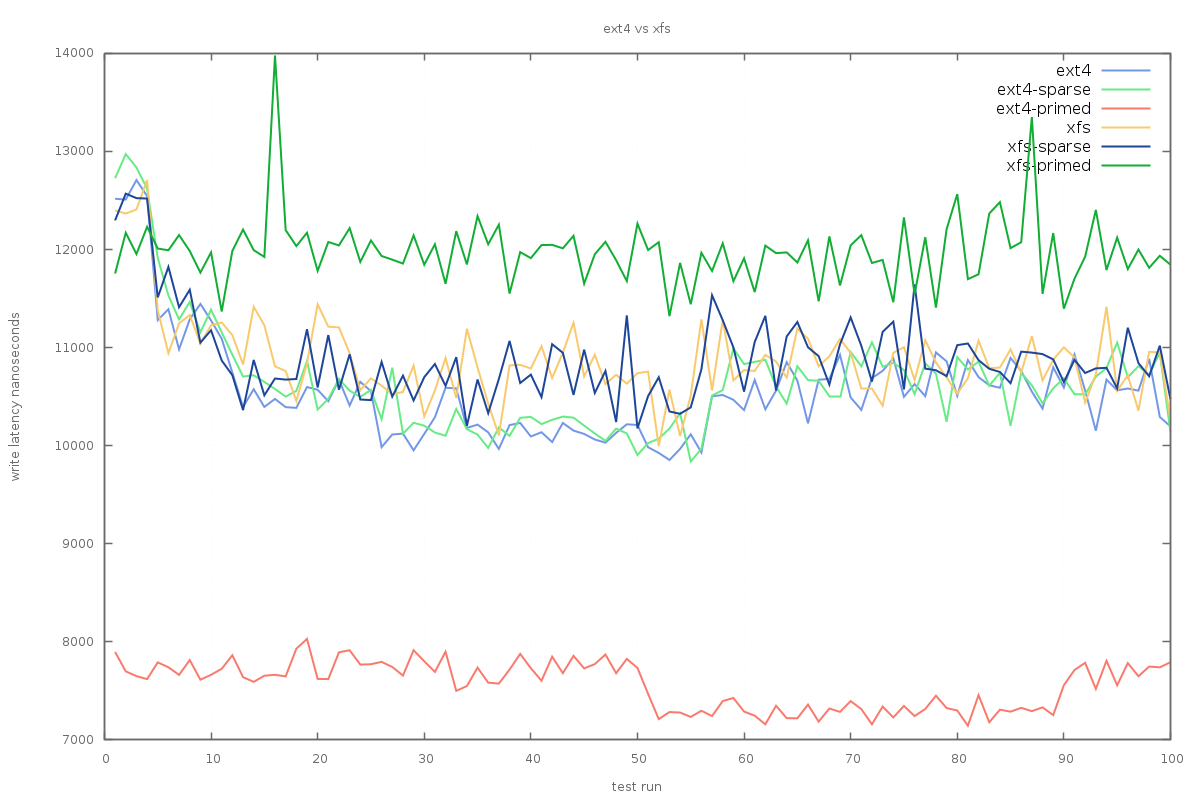
Still, since we are mostly concerned with long-tail latency, xfs is the winner so far.
Digging Deeper
You wanted a free lunch?
We have another workload for which we care about the file-system performance – one of our other services performs fast append-only writes to a number of journal files, but also requires that random-access reads can be done on those files.
Since we had such good results using xfs for our core services, we naturally thought it would be worth trying out for other services. Switching to xfs on the mixed-mode workload was disastrous however, with frequent long stalls on the writer thread. No such long stalls were observed when using ext4 for this workload.
When performing a file read using the read syscall, we end up calling the vfs_read function, which in turn delegates the call to the file-system’s file_operations struct by invoking the read method. In the case of both xfs and ext4, the file_operations‘ read method is a pointer to the new_sync_read function.
Here’s where things start to get interesting. The ext4 file_operations simply forward the read_iter call to generic_file_read_iter, which ends up invoking do_generic_file_read, the function that actually reads data from the kernel’s page cache.
The behaviour of xfs differs in that when read_iter is called, it delegates to xfs_file_read_iter. The xfs-specific function wraps its own call to generic_file_read_iter in a lock:
So, in order to perform a file read in xfs, it is necessary to acquire a read-lock for the file. The locks used in xfs are the kernel’s multi-reader locks, which allow a single writer or multiple readers.
In order to perform a write to an xfs-managed file, the writer must acquire an exclusive write lock:
Herein lies the problem we encountered. If you want to write to an xfs-managed file, you need an exclusive lock. If reads are in progress, the writer will block until they are complete. Likewise, reads will not occur until the current write completes.
In summary, xfs seems to be a safer option than ext4 from a data-integrity point of view, since no reads will ever occur while a writer is modifying a file’s pages. There is a cost to this safety however, and whether it’s the correct choice will be dependent on the particular workload.
Conclusion
Since moving to using xfs as our journalling file-system, we have observed no re-occurrence of the periodic latency spikes seen when running on ext4. This improvement is highly workload-dependent, and the findings presented here will not suit all cases.
When making changes to the system underlying your application, be it kernel, file-system, or hardware, it is important to re-validate any tunings or features implemented in the name of improved performance. What holds true for one configuration may not have the same positive impact, or could even have a negative impact on a different configuration.