




LMAX Exchange
Just before New Year 2017 a leap second was inserted into Coordinated Universal Time (UTC). At LMAX Exchange we had some luxury to play with how we handled the leap second. January 1st is a public holiday, there’s no trading, so we are free to do recovery if something didn’t go according to plan. This blog post is an analysis of the results of various time synchronisation clients (NTP and PTP) using different methods to handle the leap second.
Some Research
Red Hat have a comprehensive article about the different clock synchronisation software they support on their Operating Systems and each one’s capabilities. The section “Handling of the Leap Second” is especially worth a read to understand the various options and which ones would be applicable to you.
Since there’s no financial trading on New Years day, this event became a real “live test” opportunity for us. We were able to consider all the available methods for correcting time. If the leap second was inserted during the middle of the year (June 30th), chances are the next day would be a working week (and in 2016 it was) and we’d have had less options to consider.
Our platform code assumes that time never goes backwards – it is always expected to go forwards at some rate. If it does go backwards, our application logic simply uses the last highest time it saw until the underlying clock source has progressed forwards again. In other words, our platform’s view of time will “freeze” for one second if the clock is stepped back for one leap second.
During trading hours this is can be a problem. For previous leap seconds we’ve ignored the event and let NTP handle the clock drift naturally. The Red Hat page describes the clock being off for “hours” when you use this method. From our past experience it’s more like days. Ideally we want clock synchronisation to recover rapidly and we want time to always progress forward – the “client slew” method.
Most of our platform uses the tried and tested NTP Daemon for clock synchronisation. The standard NTP Daemon doesn’t have a fast slewing option, only Chrony can do this. Upgrading to Chrony before the leap second event wasn’t an option for us unfortunately, so our hand was forced to use the “daemon step” method for this leap second. We judged safer than the kernel step method (less likely to trigger kernel bugs) but we knew our platform code needed to be tested heavily.
Some of our platform uses PTPd, and it’s due to be rolled out more widely soon. PTPd’s in built help describes it’s leap second handling methods:
setting: clock:leap_second_handling (--clock:leap_second_handling)
  type: SELECT
 usage: Behaviour during a leap second event:
     accept: inform the OS kernel of the event
     ignore: do nothing - ends up with a 1-second offset which is then slewed
     step: similar to ignore, but steps the clock immediately after the leap second event
    smear: do not inform kernel, gradually introduce the leap second before the event
        by modifying clock offset (see clock:leap_second_smear_period)
options: accept ignore step smear
default: acceptNTP Planning and Expectations
The plan was to have NTP step and PTP ignore the leap second.
Telling NTPd to step the clock is simple – we just needed to remove the “-x” flag from ntpd, but we had to make sure our platform code would handle it. Â To do this we isolated one of our performance test environments and set up a fake stratum 1 NTP server by fudging a stratum 0 server. The configuration for this fake NTP server is:
restrict default kod nomodify notrap nopeer noquery
restrict -6 default kod nomodify notrap nopeer noquery
restrict 127.0.0.1
restrict 127.127.1.0
restrict -6 ::1
restrict 10.101.0.0 mask 255.255.0.0 notrap nomodify
server 127.127.1.0
driftfile /var/lib/ntp/drift
fudge 127.127.1.0 stratum 0
leapfile /etc/ntp/leap-seconds.list
We set the fake NTP server’s system clock to Dec 31st 23:45:00, force sync’d all performance machines to this NTP server, then started a performance run. Â This particular run generally takes 10 minutes to get going so by 23:59:59 the environment would be running it’s normal performance load, which is a simulation based on real production traffic patterns. This is one of the best tests we can come up with to simulate what would happen if the leap second occurred during business hours.
This leap second test was repeated a number of times and, as expected the timestamp 23:59:59.999 was used for the second time the clock ticked 23:59:59. Once the clock moved to 00:00:00 the exchange time progressed forward normally.
PTP Calculations
ptpengine:panic_mode=n
clock:leap_second_handling=ignore
clock:max_offset_ppm=1000
The first option is to stop the PTP daemon entering panic mode, which can result in the daemon stepping the clock (we want to avoid steps).
The second option simply tells PTPd to ignore the leap second from upstream, which will begin the slewing process after the leap second event occurs.
The third option sets the maximum frequency shift of a software clock. It’s measured in Parts Per Million, where 1ppm is a shift of 1us per second. A value of 1000 means that we should be able to recover the clock by 1ms every second, which is 1000 seconds to recover from the leap second event.
There is also a default setting “clock:leap_second_pause_period=5” which makes the PTP daemon stop doing clock updates for 5 seconds before and 5 seconds after the leap second event, basically as a safety measure.
1000 seconds is 16 minutes and 39 seconds, adding the 5 second pause period we estimate that our PTP disciplined server clocks should be back in sync by 00:16:44 on January 1st.
What Actually Happened: NTP
The actual leap second event over all was fine. For the NTP disciplined servers, the testing of our code held up and as expected, our platform stopped processing for 1 second until real time caught up with it’s view of time. If we look at the clock drift of one of our NTP disciplined servers at this time, there’s no perceivable clock drift after Sunday 00:00. Note the scale of the graph is “milli” milliseconds, so microseconds (the graphing engine that captured this leaves a lot to be desired):
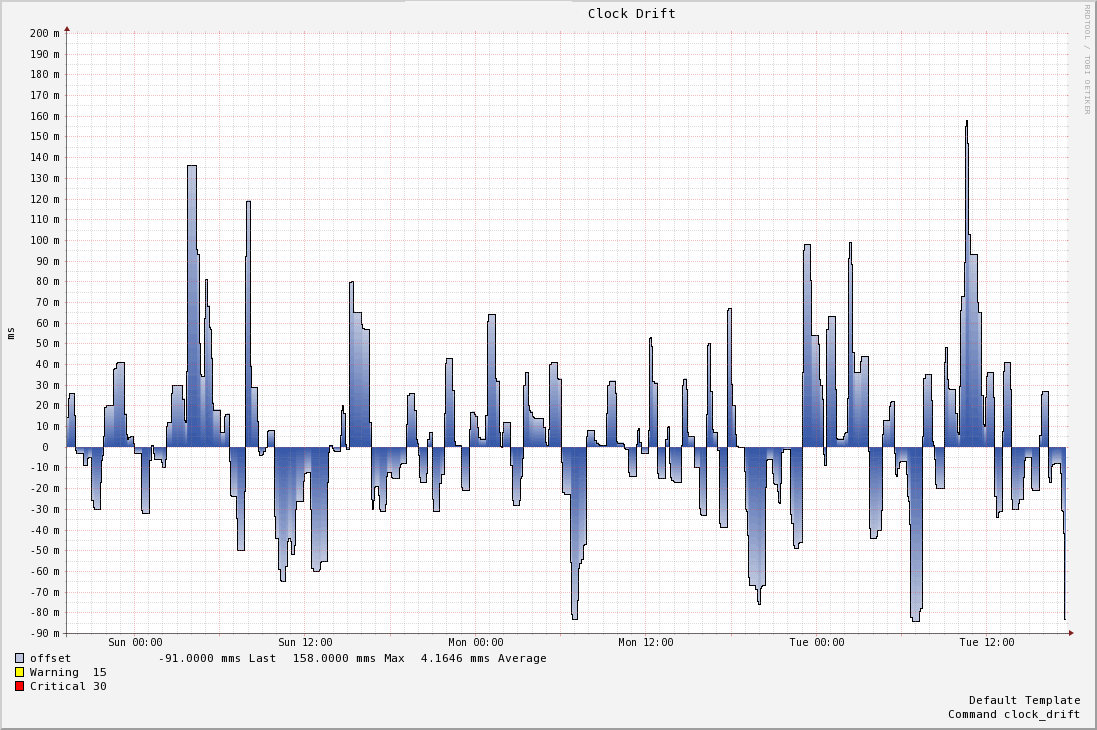
A much more interesting graph is a non-production machine that didn’t pick up the NTP configuration change that removed the “-x” flag. On this hardware NTPd ignored the leap second and disciplined the clock using it’s normal algorithms:
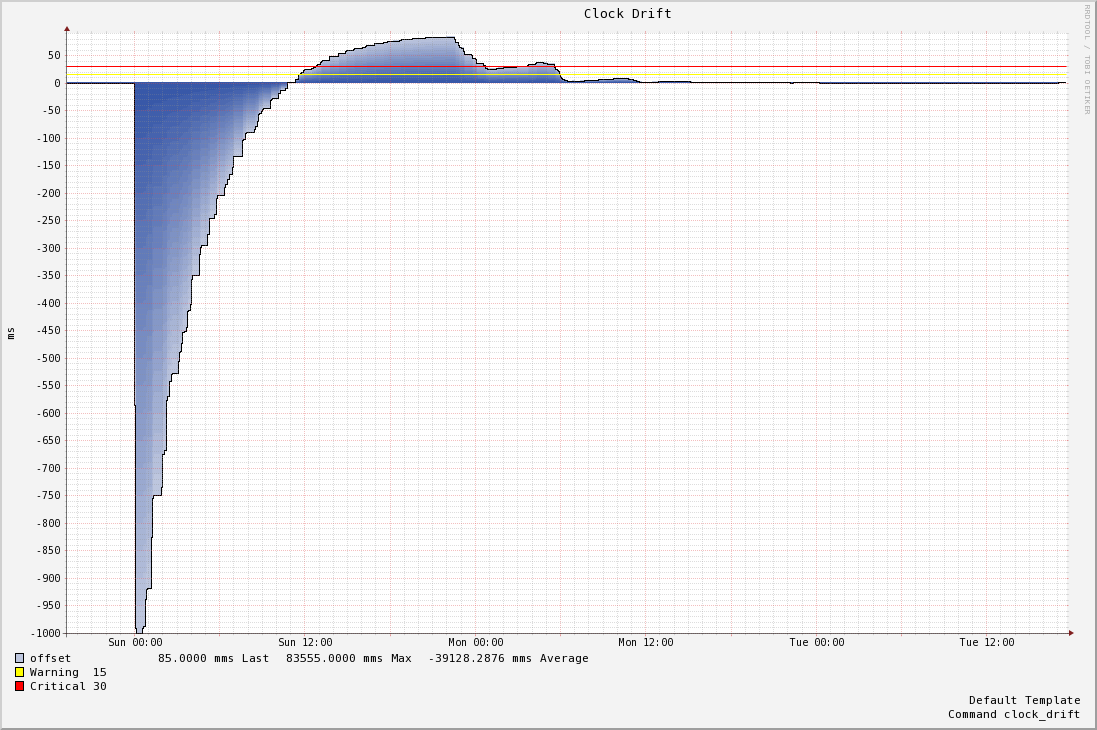
If you look at the X axis, it takes almost 12 hours for this NTP daemon to get remotely close to zero, and even after that it’s not until Monday 12:00 that the system clock is within 10ms offset. This behaviour fits our observations during the previous leap second – it took much longer recover than we expected.
The ntpd man page talks about the maximum slew rate the linux kernel allows is 500ppm, so it will take a minimum 2000 seconds for NTP to correct 1 second of inaccuracy. What we’re looking at here though is days. While we will be moving almost all platform servers to PTP we will still use NTP in our estate, and thus I’d like to understand the above behaviour. We haven’t done much research into improving NTP recovery times, but I’d be surprised if there’s not a way to tune the daemon to bring this down significantly.
A simpler option of course is to just replace ntpd with chronyd. Chrony supports a client slew method and while I don’t have any hard data, Red Hat describe chronyd’s leap second recovery as “minutes”.
What Actually Happened: PTP
I calculated it would take a little over 15 minutes for PTP to bring the clock back into sync. It actually took 45 minutes. Â While my math was technically correct, PTPd didn’t behave as I expected and I overlooked another other architecture feature that affected the recovery time.
When using PHC Hardware Timestamping the PTPd daemon manages several clocks. The Master clock is whatever interface the PTP signal is coming over, and then there’s the system clock which is a slave of the master clock. If the interface configured is also a Bonded interface, then any non-active interfaces are also managed as slave clocks.
Slave clocks are synchronised from the master clock using the same algorithm and rate limits, but more importantly is slave clocks are not synchronised until the master clock is stable (ie: the LOCKED state). So what actually happens is the master clock – which from our graph below is the PHC device attached to interface em1 – synchronises it’s time to the upstream PTP master clock first, and only once it is in sync do the rest of the slave clocks in the server start to be disciplined:
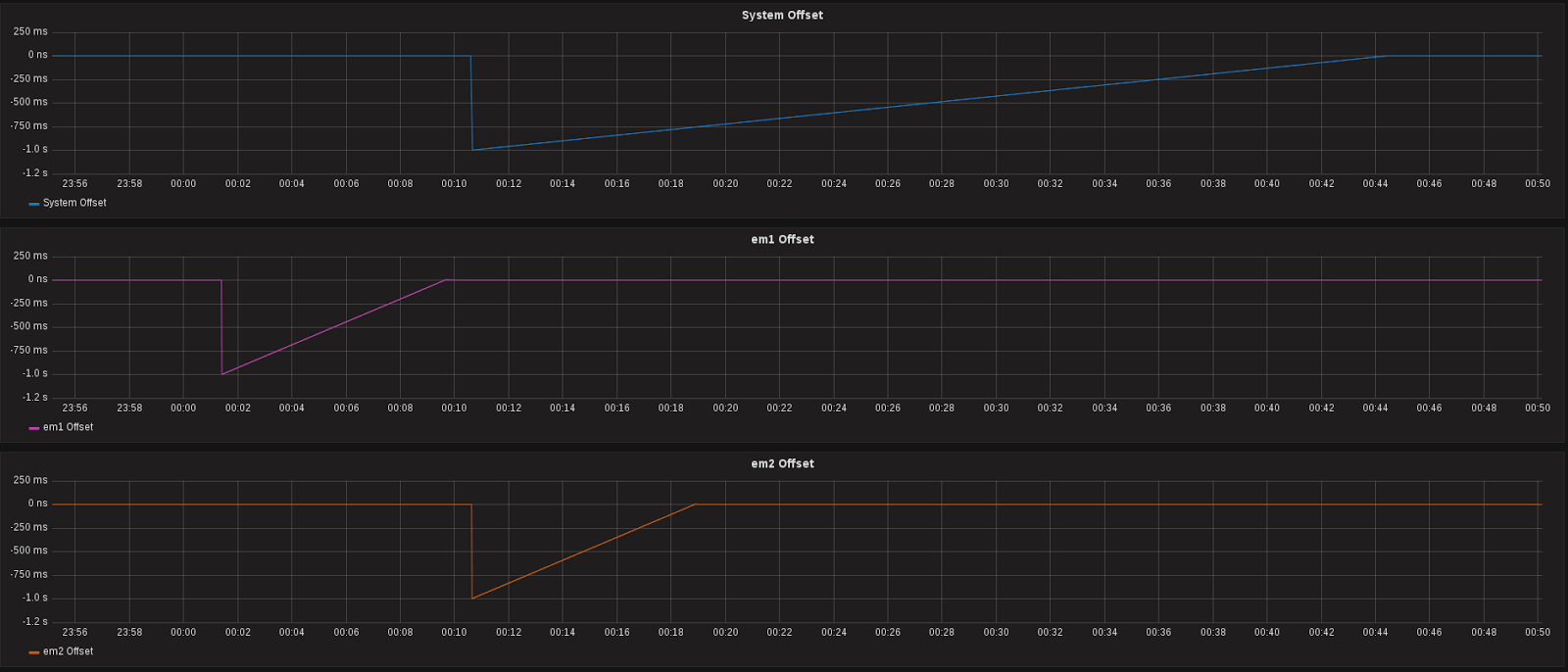
This is why the offset of em1 begins to track back into sync a little after 00:01:00. em2 and the System clock only begin to synchronise after 00:10:00, once em1 is LOCKED. Â Why are the NIC clocks synchronising faster than the System clock though?
PTPd has the “clock:max_offset_ppm_hardware” setting which defaults to 2000ppm, which is also the daemon’s maximum. This means it will take 1000000/2000/60 = 8.33 minutes to correct one second of offset. However the System clock is a software clock, who’s rate is controlled by the “clock:max_offset_ppm” option which we specifically set to the maximum value of 1000ppm. The system clock should be recovering by 1ms every second but it’s actually taking 2 seconds to recover 1ms, clearly seen in the slope of the graph if you zoom in (see below):
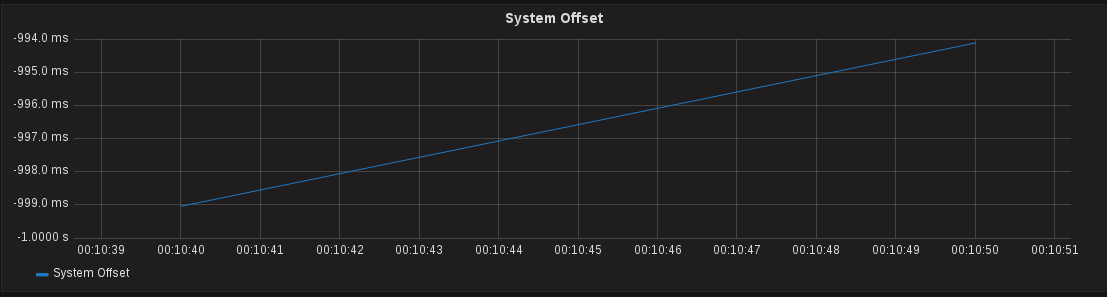
It looks like our value of 1000 for “clock:max_offset_ppm” didn’t do anything. Wojciech Owczarek provided the answer – it is a known issue with the version of PTPd we’re running. Support for slewing system clocks above the kernel maximum of 500ppm isn’t finished yet, but will be in the final version.
While it’s not as fast as I’d predicted, PTPd recovery is a lot faster than our NTP recovery. Â We still want to know why our standard NTP recovery time is measured in days rather than hours, but that’s less important if we move to Chrony for NTP.